



销售一对一模拟演习:练习密度决定技能转化率
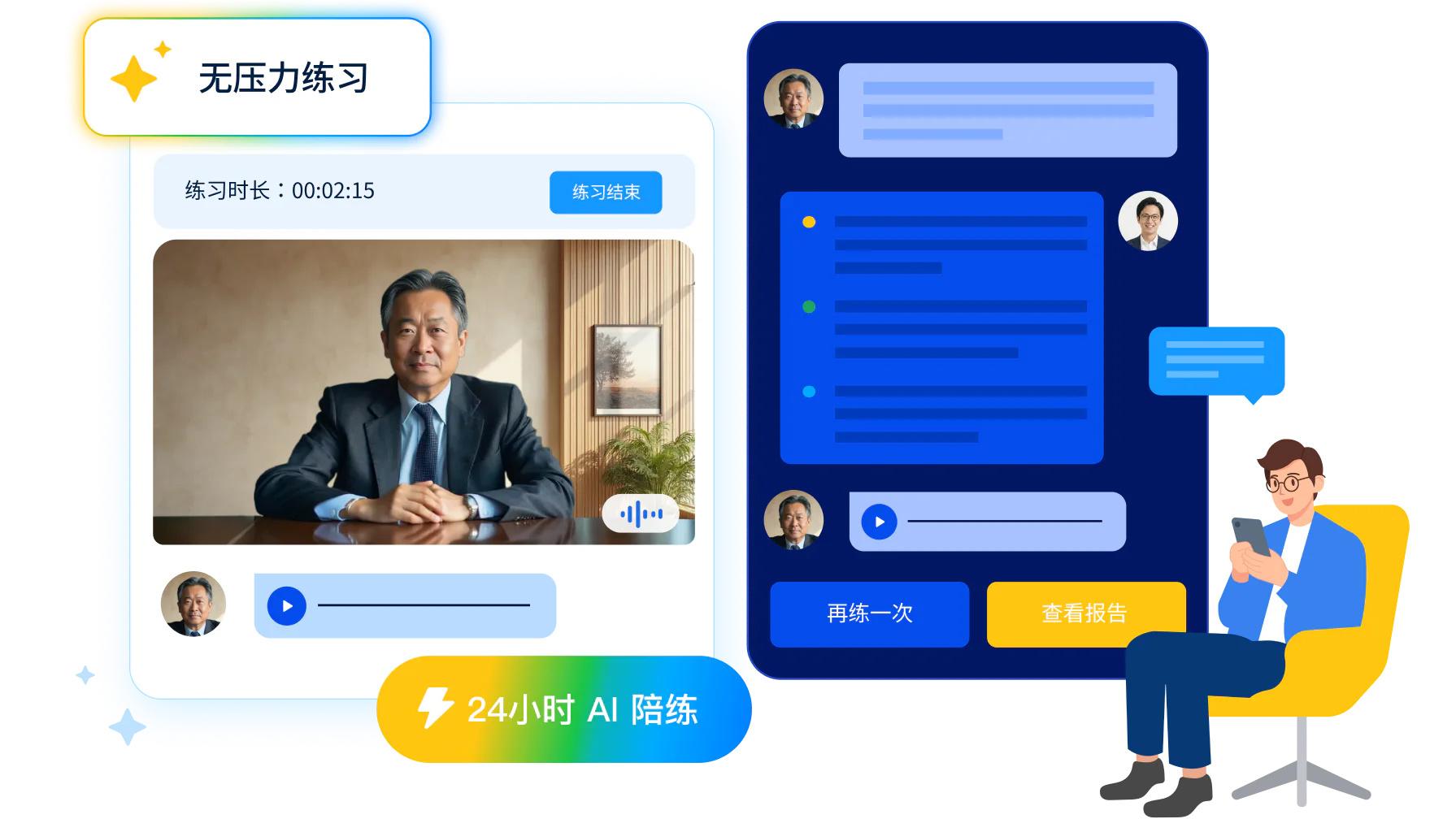
销售一对一模拟演习,指销售和一位对手逐句还原真实拜访,把课堂上学到的方法练成临场反应。一次完整的演习包含角色设定、模拟对话、即时复盘三段。这三段都到位,演习才能把知识真正变成开口时的本能。
演习的价值由对话密度决定
一次完整演习如何发生
一次销售一对一模拟演习,从开始到结束分三段。角色设定段,先定清楚本次练哪个客户、哪个拜访环节、要达成什么目标,比如练一次面对挑剔决策人的方案陈述。模拟对话段,一人扮演客户、一人应对,按真实拜访的节奏推进,时长一般控制在五到十五分钟。复盘段,对话结束后立刻从三个角度展开,销售自评、扮演客户者的反馈、观察者的结构化点评。三段都重要,而真正决定演习价值的,是其中开口练习的那一段。
决定效果的是开口次数
多数人把演习见效慢归因到剧本写得不够细、场景设计得不够多。归因停在剧本一层,看到的是内容问题。再往下钻一层,演习能不能见效,由一件事决定,就是每位销售真正开口的次数。一句应对话术能在客户突然压价时脱口而出,取决于这句话之前练过多少遍。剧本再细,如果一名销售一场演习只轮到两三次开口,话术依然停在看过的阶段,没有变成应答如流的反应。难点不在剧本,在每个人的练习密度怎么保障。
传统一对一演习的三处断点
模拟演习靠次数累积反应,一句应对话术练够上百遍,才能在被客户突然质疑时自然说出。但一对一演习要凑成一对,一名老销售对一名新人,配一次就占掉双方一段完整时间。能配对的资深销售就那么几位,多数人一周轮到一两次,靠这个频次累积反应,远远不够。
练习机会本来就少,少数几次的质量就更要紧。但扮演客户的人往往凭手感点评,今天讲一套、明天换一套,同一个问题不同人给的反馈对不上。错的应对话术被当成对的反复巩固,等真到了客户面前才发现,之前练的版本本身就有问题。
没有统一反馈,也没有过程记录,销售自己同样说不清几次演习下来到底有没有效果。哪个环节比上周顺了、哪个环节还在原地,都没有依据。看不到进步,就谈不上针对性改进,剩下的只有练过这个动作本身。
每位销售都能高频开口练习

不再受配对资源限制
每位销售都能拿到足够的开口次数,不必等资深销售腾出时间配对。UMU Roleplay Chatbot 用 AI 客户随时接受对练,不限人数同时在线,一名新人想练几遍就练几遍。AI 客户的回应每次都不一样,可能追问细节,可能直接压价,同一个难点在不同客户角色下反复出现,开口密度一下提上来。
每次练习都拿到统一反馈
反馈标准统一不再凭手感
每次练完都能拿到一致的反馈,不再因为扮演客户的人不同而对不上。UMU 把企业认可的拜访策略和评估标准预设进 AI,对话结束就按开场白、探询、信息传递、异议处理、结束语五个环节逐项打分。错在哪、对在哪当场说清,错的应对话术不会被当成对的反复巩固。整个过程没有旁人围观,销售放下顾虑反复试错。
每个人的进步都看得见

进步过程被完整记录
每个人的练习都留下数据,进步过程一目了然。UMU 为每位销售建起跨时间的能力曲线,从首次分到最高分,按环节、按异议类型拆开看。管理者能精确到某人在竞品应对上连续三次失分,探询环节已从 55 分进步到 80 分。模糊的这人表现一般,变成有依据的针对性辅导。
把演习练成实战能力的两家企业
体外诊断头部企业·1500 名销售

一家业务覆盖全球的体外诊断企业,5 名培训员工负责 1500 名销售的认证。
过去靠人工模拟做认证,两人对练、现场打分,一个季度才认证一轮,新人入职要等三个月才能上岗,结果还高度依赖评估人当天的状态。
换成 AI 对练后,认证随时开展、当天出结果,学员真实拜访转化率较之前提升 22.4%,培训团队从重复陪练转向高价值辅导。
全球头部制药企业·年轻 MR 梯队

一家全球头部制药企业,年轻 MR 与中高级 MR 能力差距明显。
年轻 MR 缺实战经验,中高级 MR 有经验却时间有限,传统跟访、陪访周期长、机会少,演习配不上人。
引入 AI 对话陪练高频还原真实拜访后,参训年轻 MR 在第 7 到 9 个月,与医生的有效拜访次数较培训前增加约 2 倍,增速超过有经验的中高级 MR。







