



销售培训数据分析怎么做:让培训效果有据可查
销售培训数据分析的目标,是把团队练了多少、练得怎么样、哪里还差,变成管理者看得懂的数据。它要回答的核心问题是上完课之后能力到底有没有提升,而非销售有没有出勤。一份能用的销售培训数据,应当覆盖练习过程、能力变化和环节短板三层信息。
销售培训数据分析要先看清两件事
一份培训数据通常包含的三层信息
销售培训数据分析的内容,大体分三层。第一层是练习过程数据,记录每个人练了多少次、覆盖了哪些场景。第二层是能力变化数据,看每个人从首次练习到最近一次练习,分数走出了什么曲线。第三层是环节短板数据,定位团队在开场白、探询、异议处理这些拜访环节里,哪一环失分最集中。三层数据由浅入深,前一层说明练没练,后两层说明练得有没有用。但真正难采集的,恰恰是后面两层。
能采到的多是签到数据,能力数据反而是空的
培训效果可以用一张清单来检查,完成多少课时、通过多少考试、收回多少满意度问卷。这类数据越齐全,越容易让人误以为培训已经被衡量清楚。可是参加完培训的销售回到客户面前表现如何,这些数字一个都答不上来。能力是在一次次开口练习里积累成形的,而传统培训既没有足够的练习记录,也没有统一标准的打分,能力变化这条最该被分析的曲线,往往从一开始就采集不到。真正的难点不在分析方法,在于可被分析的能力数据从何而来。
培训数据能说明效果要同时满足三件事
能反映能力的数据,必须来自销售实际开口练习的过程,课后填的问卷只记录态度,练习过程才记录行为。一份销售培训数据如果只有出勤和满意度,没有每个人在拜访环节里说了什么、怎么应对客户追问,它就还停在衡量参与度,没碰到能力本身。
同一段练习,换个培训师打分可能差出十几分,靠人凭印象给评语,团队之间的数据没法横向比。数据要能用来分析,前提是所有人用同一把尺子量。统一的评估标准把开场白、探询、异议处理拆成可观察的得分点,谁强谁弱才落在同一个坐标系里。
一句团队平均分提升了,对辅导几乎没有用。有用的数据要追得到人、拆得到环节,知道某个销售在竞品应对上连续三次失分,也知道他的探询环节最近三次稳步上升了二十多分。颗粒度到了这一层,管理者才知道该辅导谁、辅导哪一环,数据分析才真正接上了辅导决策。
每次练习都留下可分析的行为记录

练习行为被完整记录
销售在 UMU Roleplay Chatbot 里面对 AI 客户完成一次完整拜访,从开场白到结束语每一句应答都被留存下来。AI 客户会主动追问、压价、提竞品,销售怎么接、接得怎么样,都进入可回看的练习记录。采集到的不再是出勤和满意度,而是能直接反映能力的真实行为样本,能力数据分析从这里才有了原料。
全员练习用同一套评估标准

评估标准统一且透明可调
企业可以把销冠验证有效的话术和各环节评估标准预设进 AI 判分基准,全员在同一套尺子下练习和打分。开场白、探询、异议处理各占多少权重,每一项怎么算得分,企业自己设定,也看得见。打分不再随培训师的主观印象浮动,团队之间、不同时间之间的数据这才具备横向可比性,分析出来的结论也站得住。
数据追得到每个人和每个环节
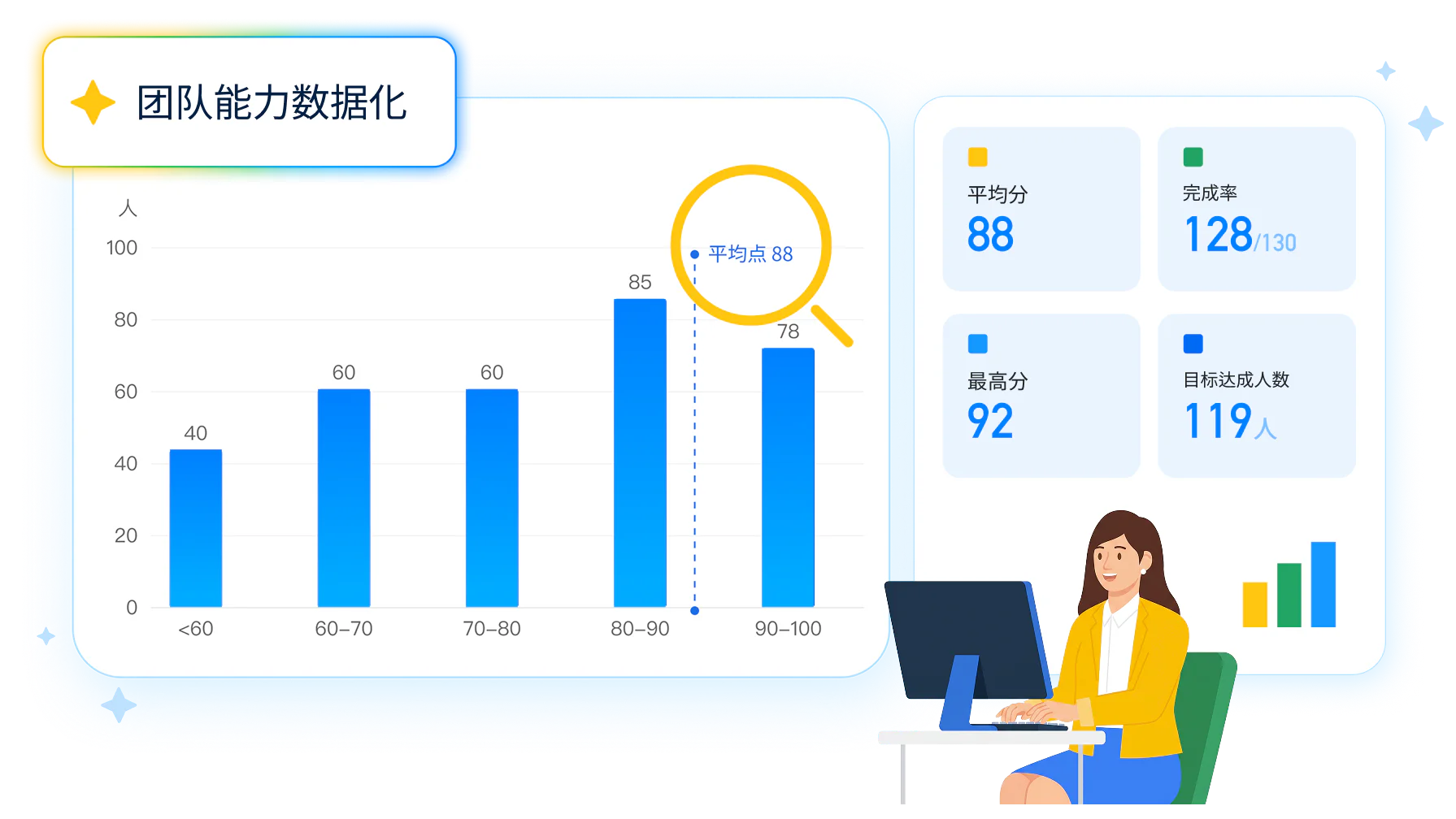
颗粒度到个体和环节
管理看板把团队练习数据按环节、信息点、异议类型逐项拆开。一线主管能看清某位销售在竞品应对上反复失分,也能看到他的探询环节正在稳步爬升。培训负责人则能分清这是个体问题还是团队的系统性短板。向上汇报时拿出的不再是完成了多少次练习,而是异议处理平均分提升了多少、获认证学员的拜访转化变化了多少。辅导决策有了客观数据做依据,不再依赖管理者的个人印象。
用数据验证培训效果的两个标杆
全球头部制药跨国企业

这家全球头部制药跨国企业每条产品线只有 3 名培训师,人工评分标准不统一,主观因素难以排除,培训学了但行为层面是否提升一直无法量化。
引入 UMU Roleplay Chatbot 承接大规模标准化训练后,累计 3,662 名销售参与、训练超过 102,834 人次,全部沉淀为可分析的练习数据。数据可视化清晰验证了训练成绩与训练次数之间存在明确的正相关。
区域型保险代理品牌

一家区域型保险代理品牌想用严谨证据回答一个问题,AI 练习到底有没有效,需要拿出可对比的数据来证明,而非停留在主观感受。
项目设计了受控对比实验,15 名评价者观看约 150 名保险销售的对话练习录像,在 5 个独立维度按 5 分制评分。结果显示,使用 AI 练习的实验组在全部 5 个维度上都优于未使用的对照组,效果被数据完整验证。







