



销售模拟对话软件哪个好,看场景化落地能力
销售模拟对话软件哪个好,常被等同于功能清单的对比。真正决定培训效果的,是组织能否在自身节奏内完成落地、对话能否对齐行业拜访逻辑、训练效果能否被结构化数据证明。多数方案在演示中表现接近,部署后才暴露出场景搭建依赖供应商、对话脱离实际业务、效果难以汇报等深层差异。选型评估的核心在于:未来一年的培训项目能否在这套工具上跑出可量化的能力变化。
销售模拟对话工具的三大痛点
AI 销售陪练软件的选型评估往往停留在功能清单层面,但功能数量与真实可用性之间存在巨大落差。按演示挑选的方案在自身组织内部署时才发现需要大量定制开发,预期的天级上线变成月级等待。
主流大模型对话能力出色,但模拟客户时使用统一逻辑,缺乏行业拜访方法论与典型异议的深度沉淀。业务一线试用一轮就指出脱离实际场景,培训部门难以推动业务部门采纳,培训项目陷入推不动的困境。
软件运行后可汇报的指标停留在练习次数与参训率,培训投入与业务能力之间没有结构化数据连接。当管理层询问投资回报时,培训部门难以拿出可量化的能力提升数据,预算审视压力持续累积。
选型本质看落地、深度与可量化
用科学训练驱动业绩增长
组织在评估销售模拟对话软件时,常常因功能清单的相似性陷入选型困境,落地后才发现真正决定培训效果的是三个变量:场景能否快速搭建、对话能否对齐行业逻辑、训练效果能否量化向上汇报。根因在于多数方案只解决了演示层面的能力呈现,未把搭建、运行与评估贯通为同一套训练体系。UMU Roleplay Chatbot 把这三个变量整合为统一平台,让组织在选型阶段就能锁定可落地、可量化、可演进的训练方案。
UMU Roleplay Chatbot 构建可落地的训练体系
UMU Roleplay Chatbot 提供零代码场景搭建后台与行业模板,把对话脚本配置回到业务团队手中。培训部门无需等待供应商排期,新品上市、合规升级等关键节点都能在天级窗口完成上线,选型阶段就锁定可落地的时间承诺。
经过行业验证的拜访方法论与典型场景模板内置为对话训练的底层结构。AI 按完整的拜访环节推进对话,让脚本中的每段对话都对齐真实业务的策略,业务一线验证后愿意主动采纳。
训练过程数据被结构化采集,覆盖个体进步曲线、环节失分分布、团队能力变化趋势。培训项目的投资回报有可量化的能力提升数据支撑,向管理层汇报时直接拿出具体的业务指标变化。
UMU Roleplay Chatbot 支持业务人员零代码搭建场景
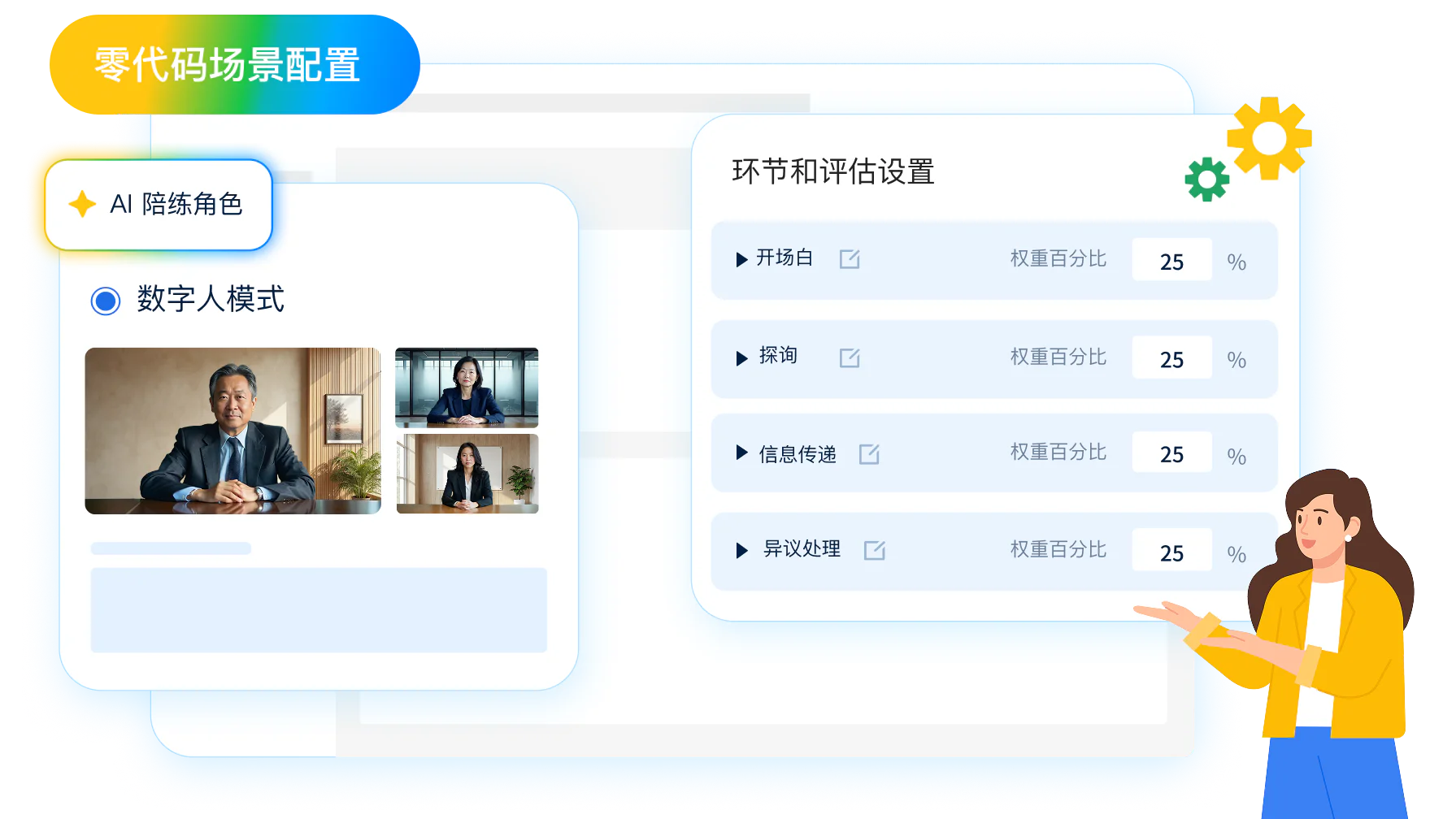
零代码后台直观操作
UMU Roleplay Chatbot 的管理后台像搭积木一样直观,无需 IT 团队介入、无需复杂提示工程,业务人员仅凭对业务的理解就能独立完成场景配置与调整。培训部门与业务团队都不再受技术资源限制,场景需要调整时业务人员自己就能改,落地不再依赖外部团队的排期窗口。
UMU Roleplay Chatbot 内置经过行业验证的拜访方法论
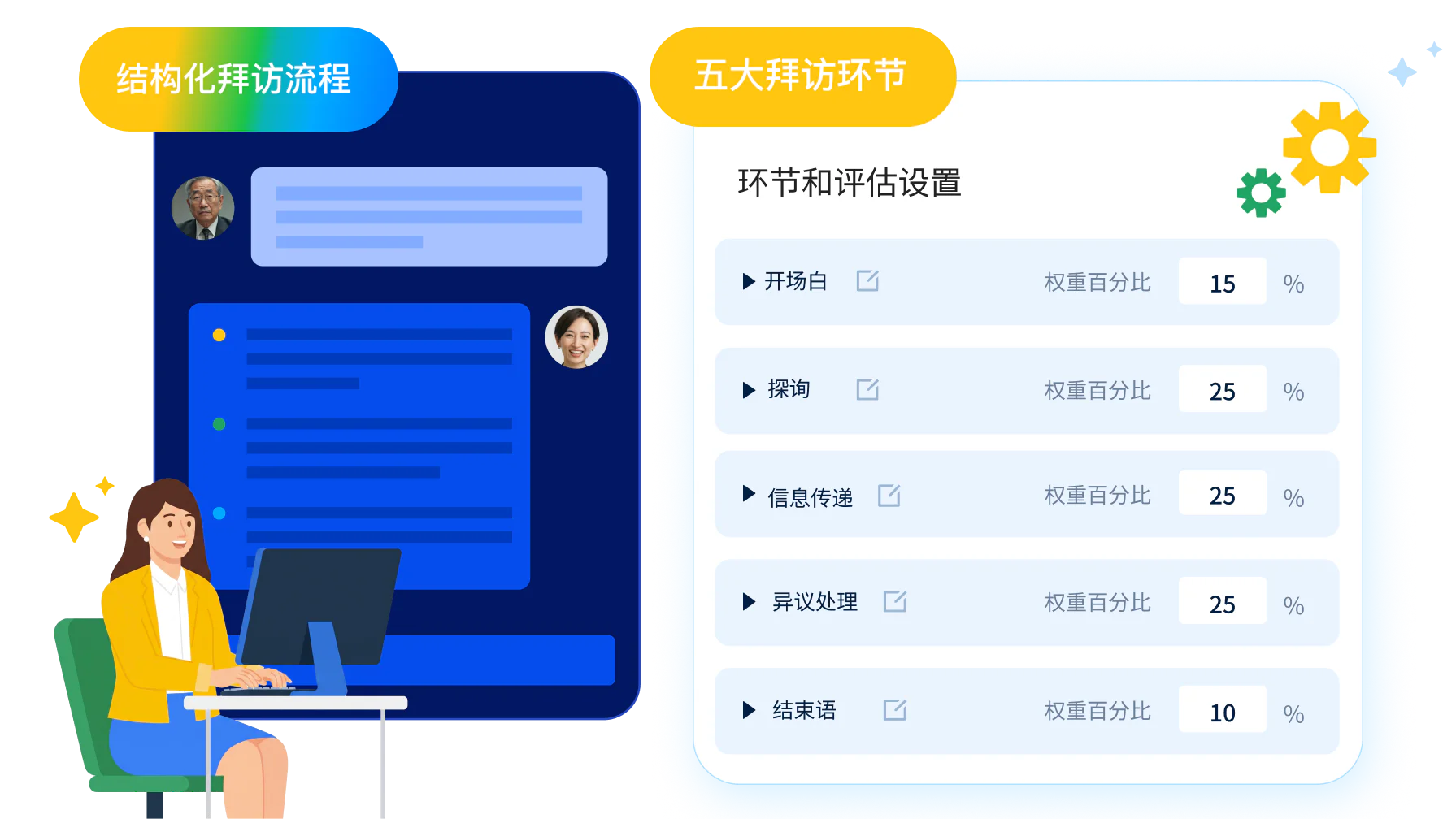
五大拜访环节作底层结构
产品内置开场、探询、信息传递、异议处理、结束语五大经过行业验证的拜访环节,作为每次对练的底层结构。脚本中的每段对话都按完整拜访的逻辑推进,让训练内容具备业务一线可识别的专业深度,从选型环节就具备明确的差异化判断依据。
UMU Roleplay Chatbot 提供个体进步曲线与团队诊断

数据可视化能力诊断
训练数据按环节、信息点、异议类型做结构化拆解,覆盖个体进步曲线、团队共性短板与多维度筛选。培训部门精准识别辅导对象与辅导重点,向管理层汇报时拿出异议处理环节平均分提升、认证学员拜访转化率变化等可量化的业务指标。
各行业培训团队的选型落地路径
体外诊断行业头部企业

5 名培训员工要负责 1500 名销售的能力认证
选型 AI 陪练替代人工认证环节,AI 即时生成评分
拜访转化率提升 22.4%,认证从每季度一次变为随时按需
区域型保险代理品牌

决策层需要严谨证据回答 AI 训练效果是否经得起验证
设计 5 维度受控对比实验,对照组与实验组并行评估
5 个评价维度全部验证实验组表现更优
高端女装品牌

500 多家门店跨区域无法靠传统带教规模化
多个差异化 AI 客户角色覆盖高端客群对话特征
当年双 11 私域 GMV 同比增长超 90%,会员转化率 +42%

