



销售模拟场景设计:颗粒度决定练习价值
销售模拟场景设计,要回答的是一组很具体的问题:练哪个客户、练哪个拜访环节、练到什么程度算过关。同一个销售技能,配一个笼统的通用场景,和配一组贴近真实业务的差异化场景,练完之后的迁移效果完全不在一个量级。一套场景搭得好不好,从设计阶段就已经决定了。
一套场景从搭建到练完要经历什么
一套销售模拟场景如何设计出来
一套销售模拟场景从无到有,通常分三个阶段。第一个阶段定客户,明确这次要让销售面对谁,是只比价的客户,还是反复追问竞品参数的客户。第二个阶段定环节和目标,圈出要练的是开场白还是异议处理,再定一个明确的过关标准。第三个阶段把场景放进练习,让销售真正开口走一遍,练完给出反馈。三个阶段都要做扎实,一套场景才算完整。其中真正决定练习价值的,是第一个阶段的设计精度。
设计精度不够,后面两步都会落空
做场景设计时,常见的做法是把问题归到场景数量不够多,于是不停加场景、加题目。但场景数量上去了,练习价值不一定跟着上去。一套笼统的通用场景,客户角色含糊、异议节奏平淡,销售练一百遍,遇到的还是同一种好说话的客户。真实拜访里那种被追问、被压价、被中途打断的压力,从设计阶段就没有还原进去。真正的难点不在场景多少,在每一个场景的设计精度,传统的人工设计方式恰恰最难做到这一点。
传统场景设计的三处断点
真实业务里的客户千差万别,价格敏感型、对比型、犹豫型各有各的难点。靠培训师凭经验一个一个手写场景,能写出来的客户类型很有限,往往只覆盖最常见的两三种。销售练熟了这两三种,遇到设计里没写到的客户类型,依旧没有应对经验。
就算把场景设计得再细,落到执行还要靠人来演。同事扮演客户时下意识会配合,不会真的板着脸追问,也不会在销售答得磕巴时中途离场。设计稿上写好的高压情境,到了真人对练里被磨平大半,销售经历的还是一场友好的排练。
压力还原不到位,练完的评判就更难有依据。同事点评各凭主观,培训师人手有限顾不过来,设计阶段定下的过关标准没人逐项核对。一套场景到底练没练到位,最后只剩下练过这个动作本身,最初设定的训练目标无从验证。
各类客户角色在练习阶段就能配齐

多种客户角色一次配齐
价格敏感型、对比型、犹豫型这些真实客户类型,不再依赖培训师一条条手写。UMU Roleplay Chatbot 支持自定义客户的职位、性格和沟通风格,同时配出多个差异化 AI 客户角色,再借助行业模板一键补齐常见画像。设计一套场景,覆盖的客户类型从两三种扩展到一整组,销售提前经历的客户面也随之变宽。
设计里的真实压力练习时如数还原
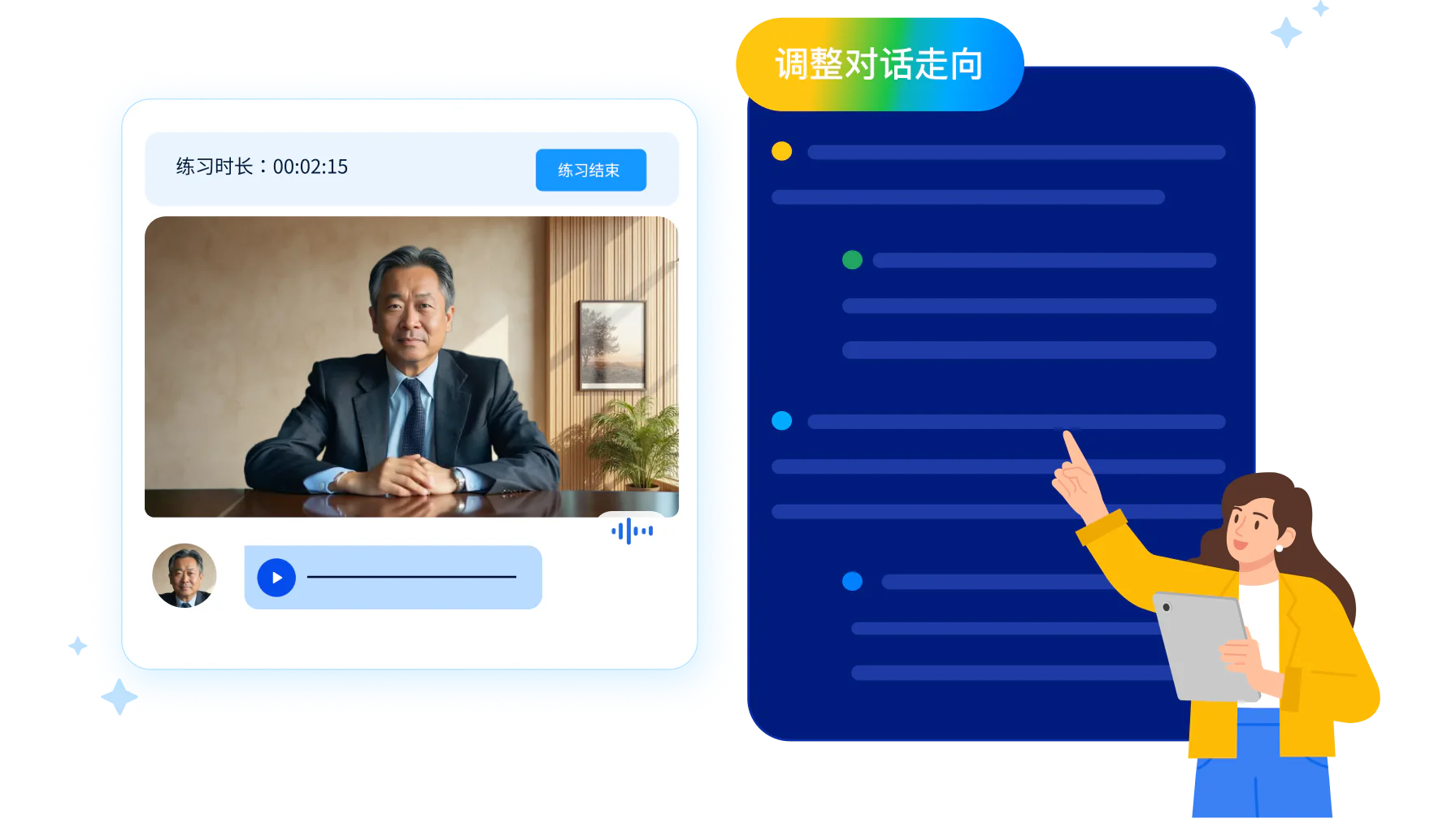
AI 客户不配合也不留情面
设计稿上写好的高压情境,这次有人如实执行。AI 客户会根据销售的回答动态调整态度,销售强硬它就抗拒,销售含糊它就追问,还能预设价格异议和竞品比较,在对话中主动抛出。再加上限时压迫,复刻医生只给几分钟、客户随时离场的真实节奏。设计阶段定下的那股压力,练习时一分不少地还了回来。
设计时定的过关标准逐项可核对
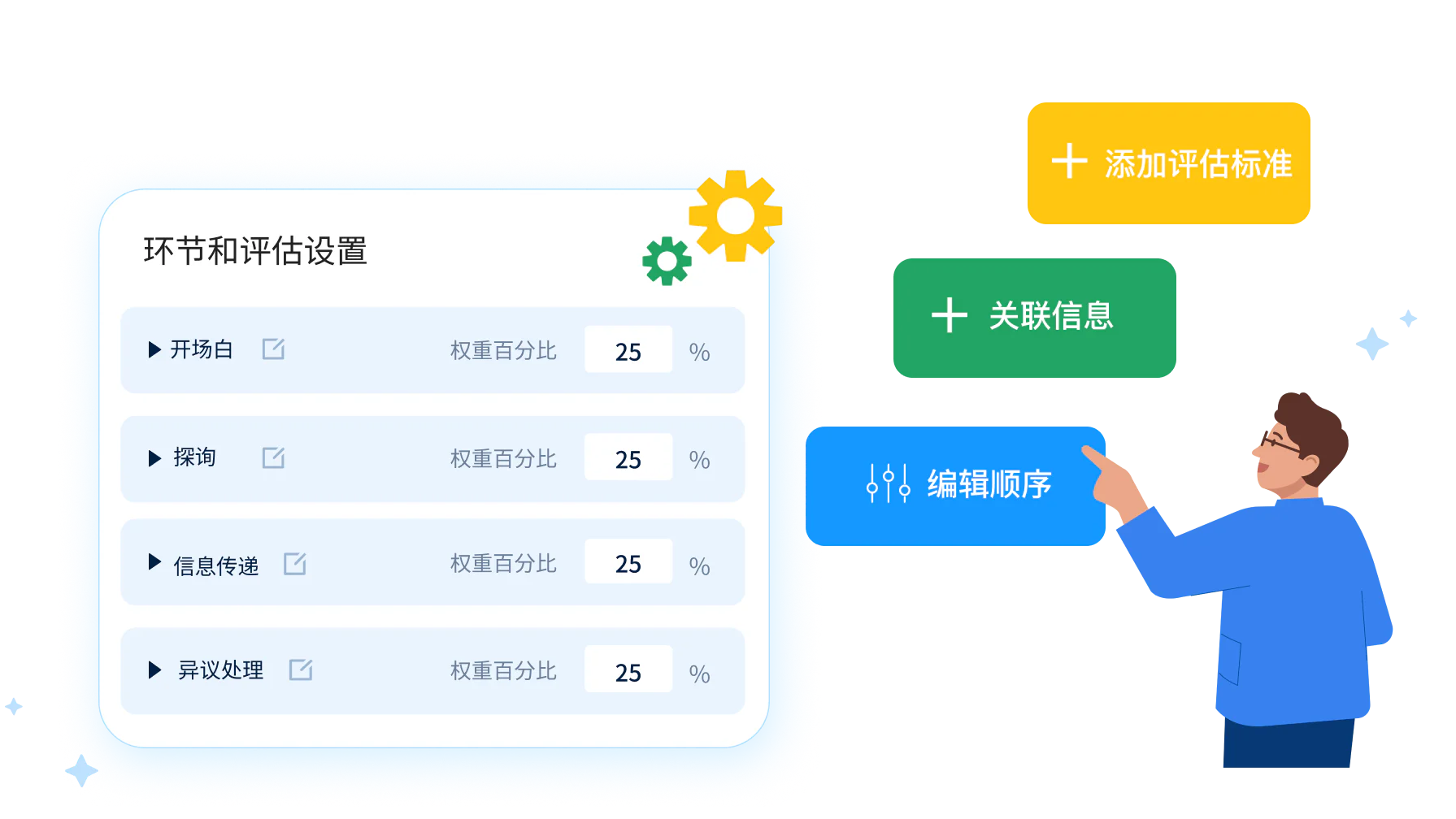
过关判据写进评估底层
设计阶段定下的过关标准,这次有了统一的核对依据。企业可以按自己的销售方法论,给每个拜访环节设置评分维度和权重,把判据写进 AI 评估的底层基准。对话一结束,系统就按这套标准逐环节打分,输出结构化报告,精确指出哪个环节失了分。一套场景练没练到位,对照报告就有了客观答案。
把场景配到真实业务里的两家零售品牌
知名童装企业

一家知名童装企业,重点战略是提升客单价和推广储值会员,落地全靠门店导购的话术。
过去人工设计的场景只覆盖少数几类顾客,跨区域门店练的还不统一,前一年大促目标没达成。
用 UMU Roleplay Chatbot 配出犹豫型、价格敏感型、赶时间型等多类 AI 消费者后,合作后第一个双 11 业绩达成率 128%,储值会员同比增加 28.1%。
多类顾客角色补齐覆盖盲区。
高端女装品牌

一家在国内外超过 100 个城市开有 500 多家门店的高端女装品牌,把重心转向高端私域会员。
新导购没和外企高管、时装买手这类高端客户对话的经验,靠同事扮演也练不出那种对话压力。
UMU Roleplay Chatbot 按高端客群特征配出多个差异化 AI 客户角色,导购在练习中提前经历各类难应对的对话,合作当年双 11 私域 GMV 同比增长超 90%,会员转化率同比增长 42%。
高端客户对话提前练到位。







