



情景模拟推销异议处理,让拜访从容应对
情景模拟推销异议处理,关键在于能否在练习中还原真实拜访的压力。销售熟记了产品手册和标准话术,可一旦客户抛出价格质疑或竞品比较,连续追问之下往往思维停滞,错失高价值商机。多数练习只停留在背诵层面,缺少真实客户的反应与施压,到了拜访现场依然难以应对。
异议处理训练的三大瓶颈
销售已经熟练掌握产品效果数据,可当客户提出同类产品价格低 30% 这类尖锐异议并连续追问时,临场思维容易停滞。练习中从没在安全环境里经历过这种压迫感,真实拜访中只能被动应付,高价值商机因此流失。
一场演练结束,销售拿到的常常只是一个综合分数,或是热情不足、逻辑不清这类模糊评语。哪个环节失分、异议处理时问题出在哪里,始终没有具体答案。缺少分环节的精细诊断,技能提升找不到清晰方向。
真人角色扮演伴随明显的社交压力,行业调研显示 62.3% 的销售对此感到紧张。练习高度依赖主管排期,协调成本高,频次远远不够。重复演练难以形成肌肉记忆,异议处理能力始终停在纸面。
训练闭环缺位,经验止步于个人
UMU Roleplay Chatbot 构建可复制的异议应对能力,让每一次拜访从容有力
团队在异议处理这一环遭遇的阻力,往往集中在同一个地方:标准话术学得很熟,真实拜访却接不上节奏。客户的质疑、追问和价格博弈带着真实压力,而日常练习给不出这种压力,能力积累没有落点。根因在于组织缺少一个能反复演练、即时反馈、还原真实情境的闭环训练环境,让销售在安全空间里把最棘手的异议提前经历一遍。UMU Roleplay Chatbot 正是面向这一缺口而来,用 AI 还原一线商谈的真实张力,让异议应对变成有准备的从容应答,帮助一线销售在拜访中稳稳掌握对话主导权。
UMU Roleplay Chatbot:高频实战,即时反馈,攻克异议瓶颈
UMU Roleplay Chatbot 构建还原实战压力的专业 AI 陪练,把企业沉淀的价格异议、竞品比较、安全性质疑预设进对话,由 AI 在恰当时机主动抛出。销售在高保真环境中反复经历最棘手的客户挑战,临场不再慌乱,应答更有准备,明显减少因异议处理失败导致的丢单。
对话一结束,AI 即时生成多维度评估报告,按拜访环节逐项打分,精确定位异议处理的失分点。模糊的综合评语升级为客观、具体、可执行的改进建议,每位销售练完就清楚自己在哪一环还需打磨,技能提升路径从此清晰可见。
练习对象是 AI,没有社交压力,也无需协调主管排期,移动端随时可发起独立对练,次数不设上限。高频、分散的常态化训练让异议应对反复内化为肌肉记忆,把枯燥的重复练习变成有目标的实战挑战,主动练习真正成为可能。
UMU Roleplay Chatbot 支持预设异议场景库

提前演练最棘手的挑战
管理员可把价格异议、竞品比较、安全性质疑等企业积累的真实异议预设进场景,AI 在对话的适当时机主动发起挑战。销售在安全环境中提前经历真实拜访里最难的瞬间,当异议不再陌生,临场便能从容应答,真实拜访中的丢单风险被提前化解。
UMU Roleplay Chatbot 支持结构化即时评估

练完即知失分在哪里
对话结束的那一刻,AI 按五大拜访环节逐项打分,生成结构化评估报告,把异议处理环节的具体失分点定位到对话中的某个动作。每次评估框架一致,不同人之间、同一个人不同时间的结果都可比较。反馈来得越快越准,每一次练习的能力提升效率就越高。
UMU Roleplay Chatbot 支持随时随地无限次 AI 陪练
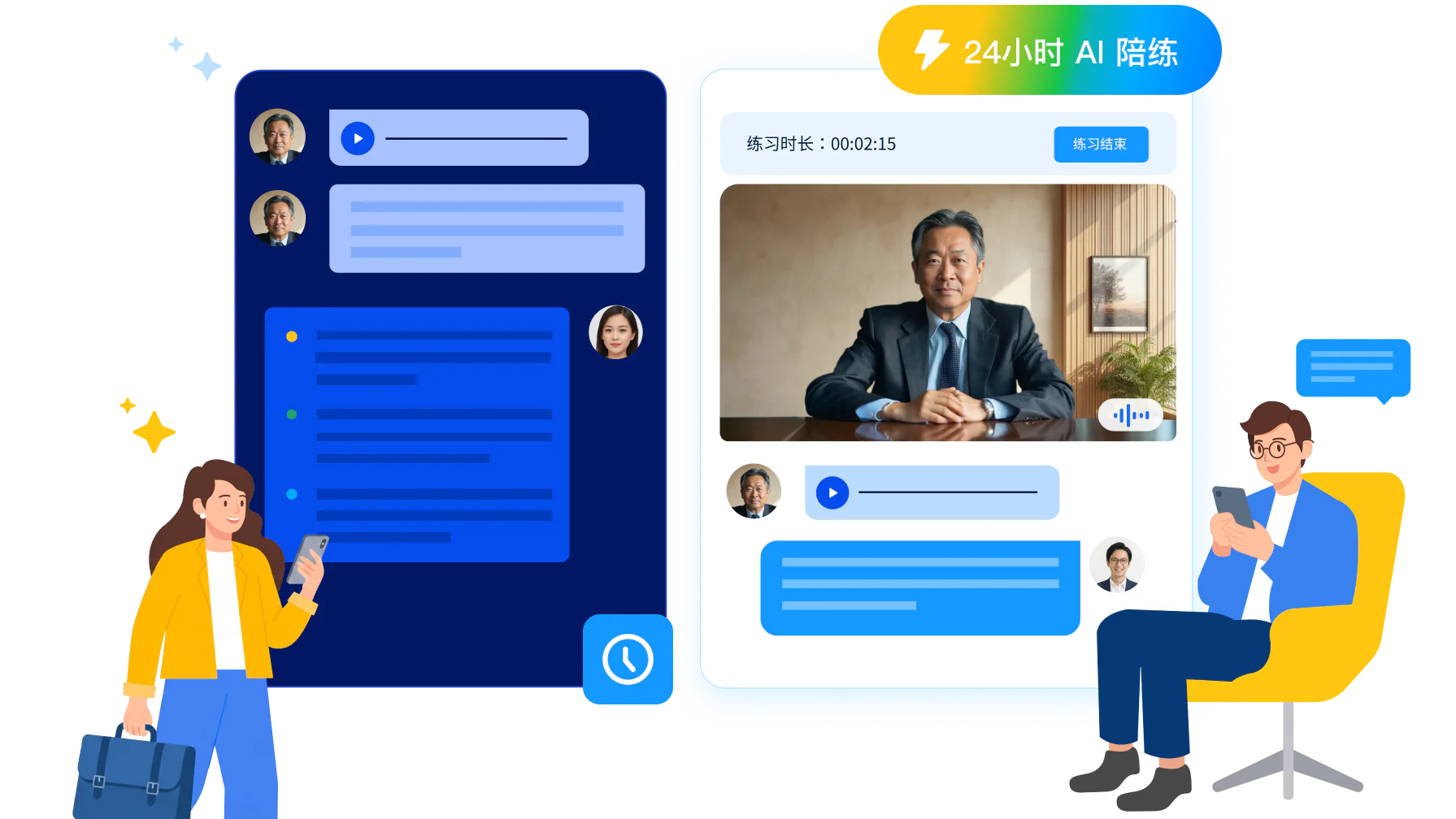
高频练习成为常态
移动端随时可练,练习次数没有上限,不必再协调主管或同事的时间。分散练习的能力内化效率远高于集中培训,每天练一个异议场景,应对能力沉淀为肌肉记忆的速度大幅提升。前文提到的达产周期由此从 60 天缩短到 30 天,高频常态化训练让团队水平稳步提升。
各行业销售团队已在使用
全球头部制药企业

年轻 MR 与资深 MR 能力差距明显,资深 MR 时间有限,难以承担大量带教任务。
引入 AI 对话陪练,让年轻 MR 高频演练真实拜访场景,积累等同于实战的对话经验。
参训年轻 MR 在结营后 7 至 9 个月,与医生的有效拜访次数较培训前增长约 2 倍。
区域型保险代理品牌

241 名销售团队需要严谨证据,回答 AI 练习到底是否有效这一关键问题。
设计受控对比实验,15 名评价者观看约 150 名销售的对话练习录像,按 5 个维度打分。
使用 AI 练习的实验组在全部 5 个评价维度上的表现,均优于未使用的对照组。
知名童装零售企业

提升客单价与推广储值会员两大目标,高度依赖门店店员面对客户时的话术水平。
AI 扮演犹豫型、价格敏感型、赶时间型消费者,连带推荐与会员话术内嵌在练习中。
合作后第一个双 11 业绩达成率 128%,储值会员人数同比增加 28.1%。







