



科研销售模拟拜访内容:还原学术拜访 3 分钟里的真实对话
科研销售模拟拜访内容,要还原的是 MR 和科室主任之间真实的学术拜访。医生留给一次拜访的有效沟通时间常压缩在 3 至 5 分钟以内,短短几分钟里既要把核心循证证据讲清楚,又要回应医生关于临床路径和安全性的疑问,同时不能触碰合规边界。新药上市窗口期一旦错过,竞品就先进了医生的处方习惯。一套能用的模拟拜访内容,要让 MR 在上岗前就经历这种密度。
一次模拟拜访要练的不只是话术
完整拜访拆成五个环节
一份能落地的科研销售模拟拜访内容,通常按学术拜访的五个环节展开:开场白、探询、信息传递、异议处理、结束语。开场白练的是几句话内建立专业印象,探询练的是听懂医生当下关心的临床问题,信息传递练的是把循证证据讲得准确又精炼,异议处理练的是回应医生对安全性和患者依从性的质疑,结束语练的是约定下一次随访的节奏。五个环节按真实拜访的时间顺序串起来,构成一次完整演练的骨架。但这五个环节的练习难度,并不在同一个量级。
异议处理最难也最少被练到
读者找科研销售模拟拜访内容时,往往以为难点在产品知识背得熟不熟。背熟循证数据只是第一层。真正决定一次学术拜访成败的,是医生突然打断、抛出竞品对比、质疑临床终点时,MR 当场怎么稳住对话节奏。异议处理最依赖临场反应,也最难在课堂和背稿里练到。传统模拟拜访内容大多停在念一遍标准话术,恰恰避开了这部分最不确定的对话。
模拟拜访内容设计的三个断点
传统模拟拜访内容里,练习环节多是角色扮演,同事扮医生,按事先准备好的问题一问一答。但真实门诊并非如此,科室主任什么时候打断、追问哪条临床数据、对竞品方案有没有成见,全是动态的。演练里练的是套路化问答,门诊上遇到的是临场变化。
学术能力的验证传统上靠地区经理陪同拜访打分,也就是协访。但 DM 的时间被大区会议、重点医院走访切碎,一个人要带十几名 MR,每名 MR 能轮上一次协访已是上限。新药上市窗口期里,真正在拟真压力下完整练过一次拜访的次数,常常不超过五次。
协访结束后给的反馈往往是开场再自然些、证据再讲透些。哪句话踩了合规边界、哪个临床终点没讲清、下次遇到同样的异议该怎么接,难以说清。MR 知道自己讲得不够好,却不知道具体失分在哪个环节。下一次演练还是同样的方式练同样的内容,改进无从发生。
把 AI 配成不同类型的医生角色

多类医生角色逐一练过
MR 在 UMU Roleplay Chatbot 里能直接面对多种 AI 医生角色,循证派的主任医师、对竞品方案熟悉的科室专家、关心患者依从性的临床医生。每一类角色的关切点和提问节奏都不一样。AI 客户角色按企业积累的医生画像配置,让 MR 练完一轮就知道面对哪类医生先讲什么、避开什么。
对话随 MR 的应答实时变化
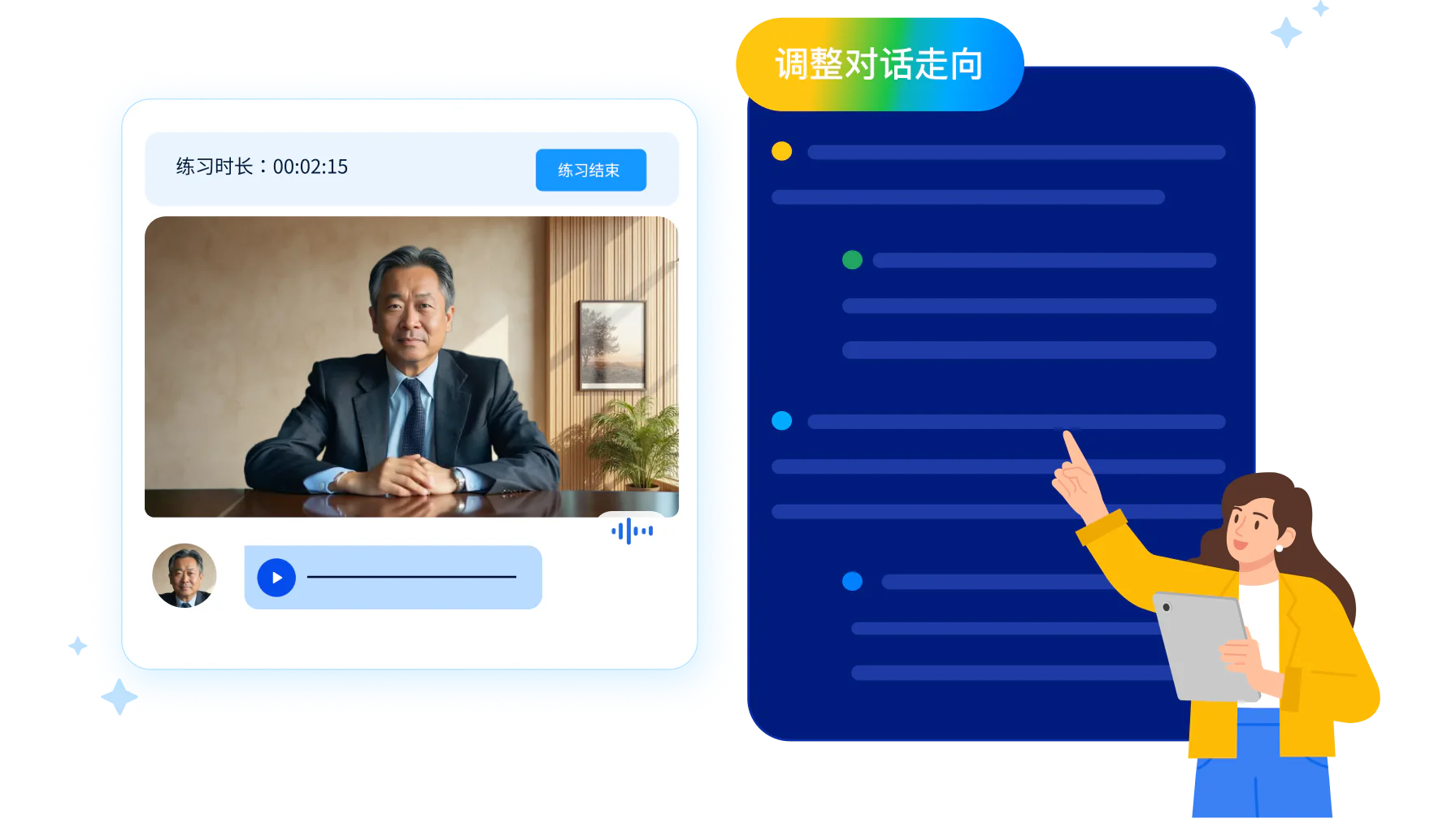
随时无限次,不占协访时间
AI 不按预设套路回复重复内容,MR 开场讲得清楚,AI 医生就顺着问下一个临床问题,讲得含糊,AI 医生的反应会变得迟疑甚至打断。这样的对练随时可发起,无限次重复,把基础的话术准确性和合规练习从协访里剥离出来,让 DM 的协访时间聚焦在策略辅导上。
对话结束即出结构化评估

逐环节打分,改进有方向
每次练习结束,UMU 即时生成结构化评估报告,按开场白、探询、信息传递、异议处理、结束语逐环节打分,精确定位失分环节和具体原因。核心产品信息和合规边界可以预设为硬性评估标准,哪句话讲得不够、下次该怎么改,当场就能看到。
医药团队已经在这样练
体外诊断头部企业

全球业务覆盖的体外诊断企业,5 名培训员工要负责 1500 名销售的能力认证。过去用人工模拟拜访做认证,两人对练加评估人员现场打分,整个流程至少一个季度,新销售入职后等三个月才能上岗,评估结果还高度依赖评估人当天的状态。
引入 UMU Roleplay Chatbot 替代人工认证环节后,认证从每季度一次变为随时按需开展,当天就能拿到结果,学员的真实拜访转化率较之前提升 22.4%。
全球头部制药企业

全球头部制药企业的 MR 梯队里,年轻 MR 和中高级 MR 能力差距明显,年轻 MR 缺实战经验,中高级 MR 有经验却没时间大量带教,传统跟访周期长、机会少。
引入 AI 对话陪练后,年轻 MR 高频练习真实拜访场景,积累等同实战的对话经验。参训的年轻 MR 在参训后 7 至 9 个月,与医生的有效拜访次数较培训前增加约 2 倍,增速反而超过了有经验的中高级 MR。







